Introduction
Whenever I give a talk on topic modeling to people not familiar with the subject, the usual question I receive is: “can you provide some intuition behind topic modeling?” Another variant of the same question is: “This is magic. How can the computer identify the topics in the documents?”. No! It is not magic. It is Math. I presented the math behind Latent Dirichlet Allocation, and an example apllication in previous posts. Here is my attempt at providing the intuition from the perspective of someone with basic understanding of simple linear regression, and a bit of matrix algebra.
Topic modeling is a form of matrix factorization. Though modern topic modeling algorithms involve complex probability theory, the basic intuition can be developed through simple matrix factorization.
Matrix factorization can be understood as a form of data dimension reduction method. In a world of “big data”, the usefulness of such method is immense. For instance, linear regression, the most used statistical tool in economics is only applicable when \(n\), the number of observations is at least as big as \(p\), the number of variables. When \(p\) is too big, we resort to some dimension reduction methods such as choosing a few variables based on theory, using stepwise, or LASSO regression. With matrix factorization, we do not have to select variables. We can just “redifined” the variables in a lower dimensional space, that is, convert the \(p\) dimensional data into \(k\) dimensional data, where \(k\) is significantly less than \(p\) (\(k<<p\)). The question is, how does that make sense? It is just matrix algebra, as you will see very soon.
The idea of dimension reduction from matrix factorization perspective
1- Consider measures of length, width, and depth. These are three variables, i.e. three dimensional data. If size is enough information we care about, then volume, that is, Volume = length x width x depth is a good variable. Thus, we can collapse the three variables (length, width, depth) into a single variable, volume and preserve the essential information needed.
2- Consider measures of height, weigth, and waist. These are three variables, i.e. three dimensional data. If size provides enough information for what we need, then some form of linear combination of the three variables (\(size = b_1\times height + b_2 \times weight + b_3 \times waist\)) will do. Thus, we collapse the three dimensional data into a one dimensional data.
3- Consider a dataset of words counts in several documents. Let’s consider the following words: college, drugs, education, graduation, health, medicaid. This is a six dimensional data. If what we care about are the concepts of education and health care, then some form of linear combination of these words counts will do. Our task consists of finding the appropriate weights so that a document having higher counts of education related words than other words gets a high value for the education concept, and low value for the health concept. And a document having higher counts of health related words than other words gets a high value for the health concept, and a low value for the education concept. Thus, we reduce the six dimensional data into two dimensional data, while preserving the essential information we care about.
The idea of matrix factorization
The idea of matrix factorization stems from the fact that any matrix can be decomposed into the product of two or more matrices. Let \(W_{n,p}\) be a matrix of dataset with \(n\) rows and \(p\) columns. We can write the same matrix as the product of two matrices, such as: \[\begin{equation} W_{n,p} \simeq Z_{n,k}B_{k,p} \label{eq:fac1} \end{equation}\]It turns out that \(Z\) preserves the essential information needed to understand variations between the \(n\) observations in \(W\).
Illustrative example
Let \(W_{n,p}\) be a spreadsheet of words counts in \(n\) documents. \(p\) is the number of unique words, and can be seen as variables. Here, \(n=6\), \(p = 5\), \(k = 2\). Let college, education, family, health, and medicaid be respectively the variables names of the \(W\) matrix.
\[ \underbrace{\begin{bmatrix} 4&6&0&2&2 \\ 0&0&4&8&12 \\ 6&9&1&5&6 \\ 2&3&3&7&10 \\ 0&0&3&6&9 \\ 4&6&1&4&5 \\ \end{bmatrix} }_{\mathbf{W_{6,5}}} = \underbrace{\begin{bmatrix} 2&0 \\ 0&4 \\ 3&1 \\ 1&3 \\ 0&3 \\ 2&1 \\ \end{bmatrix} }_{\mathbf{Z_{6,2}}} \underbrace{\begin{bmatrix} 2&3&0&1&1 \\ 0&0&1&2&3 \\ \end{bmatrix} }_{\mathbf{B_{2,5}}} \]
It is easy to check that the product holds, that is, \(Z_{6,2}B_{2,5} = W_{6,5}\). \(Z\) contains most of the information about the observations contained in \(W\). With \(Z\), we can explore, or study the variation between the observations, easily. \(Z\) is a two dimensional representation of \(W\), and a simple scatterplot can be used to explore the data, as shown in the plot below.
Z <- matrix(c(2, 0,
0, 4,
3, 1,
1, 3,
0, 3,
2, 1), byrow = TRUE, nrow = 6)
Z <- data.frame(z1 = Z[,1], z2 = Z[, 2])
plot(x = Z$z1, y = Z$z2, cex = 3)
text(x = Z$z1, y = Z$z2, labels= 1:6, cex= 1)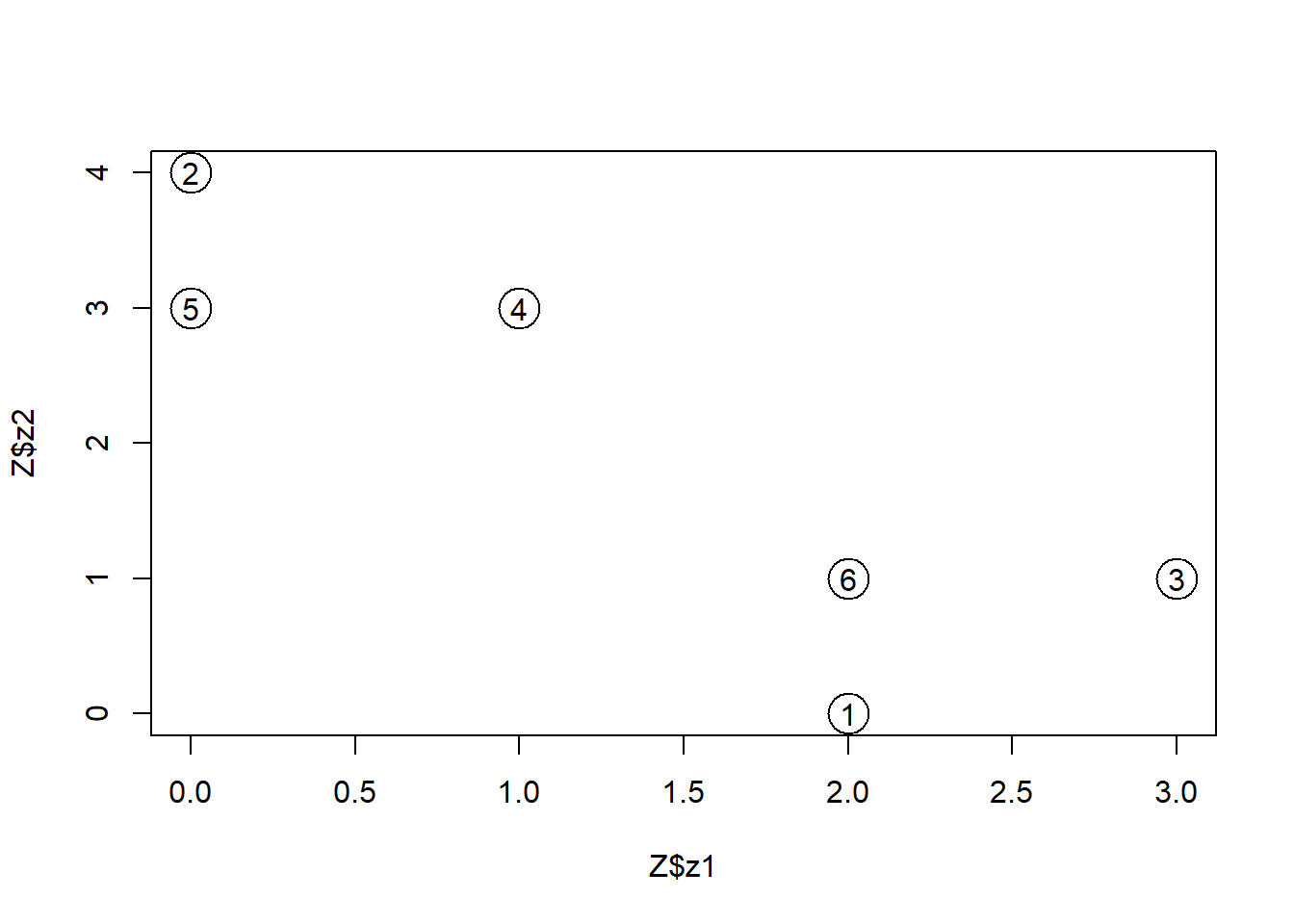
From the plot, we can deduce that observations (or documents) 2, 4 and 5 are close to each other; observations 1, 6 and 3 are also close to each other. The point here is that with a reduced dimension, it is easier to draw some insight from the data. Hence, the benefit of matrix factorization for data analysis.
For a predictive modeling exercise, we replace the \(W\) matrix with the \(Z\) matrix, and the usual tools (linear regression, logistic regression, regression tree, etc.) can be used. We do not have to understand the meaning of the new variables \(Z\). We only care about their ability to predict.
However, for exploratory and inferential data analysis, we want to understand the meaning of the new variables \(Z\). To tell a story, we have to know the meaning of the variables. We infer the meaning of the new variables by inspecting the \(B\) matrix. I will explain why that is the case shortly. For now, note that the number of columns of \(B\) is the number of columns of the \(W\) matrix; and the number of its rows is the number of columns of the \(Z\) matrix. Each row of \(B\) is used to interpret the meaning of each column of \(Z\). Row \(i\) of \(B\) is used to infer the meaning of column \(i\) of \(Z\). For instance, referring to our illustrative example above, row 1 of \(B\) has its biggest values at its first and second column, that is variables 1 and 2 (college and education) of the \(W\) matrix are dominant in the identification of the meaning of the first \(Z\) variable. Likewise, row 2 of \(B\) has its biggest values at its two last columns; the variables 4 and 5 (health and medicaid) of the \(W\) matrix are dominant in the identification of the meaning of the second \(Z\) variable. Thus, the columns of \(Z\) represent, respectively, measures of education and health concepts.
Finding \(Z\) and \(B\)
There are several matrix factorization algorithms. Factor Analysis (FA), Principal Component Analysis (PCA), Non Negative Matrix Factorization (NMF), Probabilistic Semantic Analysis (PLSA) and its variants, etc. Since our goal for this introduction is to present the basic idea, let’s present an algorithm that is closer to something we are all familiar with: Ordinary Least Squares (OLS).
Multivariate OLS
From introductory statistics, we know that for: \[y_{n,1} = X_{n,p}\beta_{p,1} + \epsilon_{n,1}\] the least squares solution for \(\beta_{p,1}\) is: \[\hat\beta_{p,1} = (X^tX)^{-1}X^ty\] We are assuming that \((X^tX)^{-1}\) exists. \(t\) stands for transpose, and \(-1\) stands for inverse.
In case you do not remember this formula, recall that: \[y_{n,1} = X_{n,p}\beta_{p,1} + \epsilon_{n,1} \Leftrightarrow X^tY = (X^tX)\beta + X^t\epsilon\] Under the assumptions of no correlation between \(X\) and \(\epsilon\), and \(E(\epsilon) = 0\), we can set \(X^t\epsilon=0\). So we have: \[X^tY = (X^tX)\beta \\ \Leftrightarrow \\ (X^tX)^{-1}X^tY = (X^tX)^{-1}(X^tX)\beta \\ \Rightarrow \\ \hat\beta = (X^tX)^{-1}X^tY \]
For a more than a single left hand side variable \(y_{n,1}\), the same formula applies; and we have: \[\hat B = (X^tX)^{-1}X^tY\] where \(B\) is a \(p\times q\) matrix, and \(Y\) is a \(n \times q\) matrix.
Multivariate OLS and matrix factorization
What does multivariate regression have to do with matrix factorization? Note that, ignoring the \(\epsilon\), we could have written: \[\begin{equation} Y_{n,q} \simeq X_{n,p}B_{p,q} \label{eq:ols} \end{equation}\]This equation is very similar to the equation \(W_{n,p} \simeq Z_{n,k}B_{k,p}\), except \(X\) is observed for the case of the multivariate OLS.
In multivariate OLS, we only estimate \(B\). For matrix factorization, we estimate \(Z\) and \(B\).
From \(W \simeq ZB\), we can solve for \[\hat B = (Z^tZ)^{-1}Z^tW\] or \[\hat Z = WB^t(BB^t)^{-1}\] The predicted values for \(W\) is: \[\hat W = \hat Z \hat B\] To estimate \(B\), we need \(Z\), and to estimate \(Z\) we need \(B\). We do not have either one. The trick is to guess some initial values for \(Z\), and use it to estimate \(B\), then use the estimated \(B\) to estimate a new \(Z\). Use the new \(Z\) to estimate a new \(B\). Continue the iteration untill some stopping criterion. Thus, we estimate \(Z\) and \(B\) iteratively (This estimation method is known as Alternating Least Squares). When do we stop the iteration?
Again, \(\hat W = \hat Z \hat B\) is the predicted values for \(W\). We itterate until the distance between \(W\) and its predicted value, \(\hat W\), is negligible. There are several distance measures, but let’s keep things simple by using the euclidean distance, or \(L_2\) norm: \[Q(\hat Z, \hat B) = ||W-\hat W (\hat Z, \hat B)||_2 = \sqrt{\sum_{i = 1}^n \sum_{j = 1}^p (w_{i,j} - \hat w_{i,j})^2}\] Thus, we minimize \(Q\), the objective function. Following is an example implementation of a simple alternating least squares algorithm.
W <- matrix(c(4, 6, 0, 2, 2,
0, 0, 4, 8, 12,
6, 9, 1, 5, 6,
2, 3, 3, 7, 10,
0, 0, 3, 6, 9,
2, 6, 1, 4, 5), byrow = TRUE, nrow = 6)
set.seed(3)
Z_init <- abs(round(rnorm(n = 6*2, mean = 0, sd = 2),0))
Z_init <- matrix(Z_init, nrow = 6)
Z <- Z_init
dist_ww <- 1e3
max_iter <- 1000
iter <- 0
while(iter <= max_iter && dist_ww >= 1e-6) {
iter <- iter + 1
ZZ_inv <- solve(t(Z)%*%Z)
B <- ZZ_inv%*%t(Z)%*%W
BB_inv <- solve(B%*%t(B))
Z <- W%*%t(B)%*%BB_inv
W_hat <- Z%*%B
dist_ww <- sqrt(sum(W-W_hat)^2)
}
W <- data.frame(W)
names(W) <- c("college", "education", "family", "health", "medicaid")
Z <- data.frame(round(Z, 2))
row.names(Z) <- paste0("document.", 1:6)
names(Z) <- c("Topic.1", "Topic.2")
B <- data.frame(round(B, 2), row.names = c("Topic.1", "Topic.2"))
names(B) <- c("college", "education", "family", "health", "medicaid")Below is the table of the least squares estimate of\(B\):
B## college education family health medicaid
## Topic.1 1.18 1.96 -0.02 0.6 0.58
## Topic.2 0.50 0.85 1.11 2.5 3.60Observe that row 1 of \(B\) has high values in columns 1 and 2 compared to columns 3, 4, and 5; and row 2 has higher values for columns 4 and 5 compared to columns 1, 2, and 3. It is reasonable to infer that row 1 (Topic.1) refers to education, and row 2 (Topic.2) refers to health.
Below is the the table of the least squares estimate of \(Z\):
Z## Topic.1 Topic.2
## document.1 3.13 0.05
## document.2 -1.55 3.58
## document.3 4.31 0.97
## document.4 0.41 2.71
## document.5 -1.16 2.68
## document.6 2.26 1.03Observe that Topic.1 has big values in documents 1, 4, and 6. Likewise, Topic.2 has big values in documents 2, 4, and 5. Hence, we can infer that documents 1, 4, and 6 are mostly about education; and documents 2, 4, and 5 are mostly about health.
We can use a scatterplot to explore the original five dimensional \(W\) data in a two dimensional \(Z\) data as follow:
plot(x = Z$Topic.1, y = Z$Topic.2, cex = 3,
xlab = "Topic.1", ylab = "Topic.2")
text(x = Z$Topic.1, y = Z$Topic.2, labels= 1:6, cex= 1)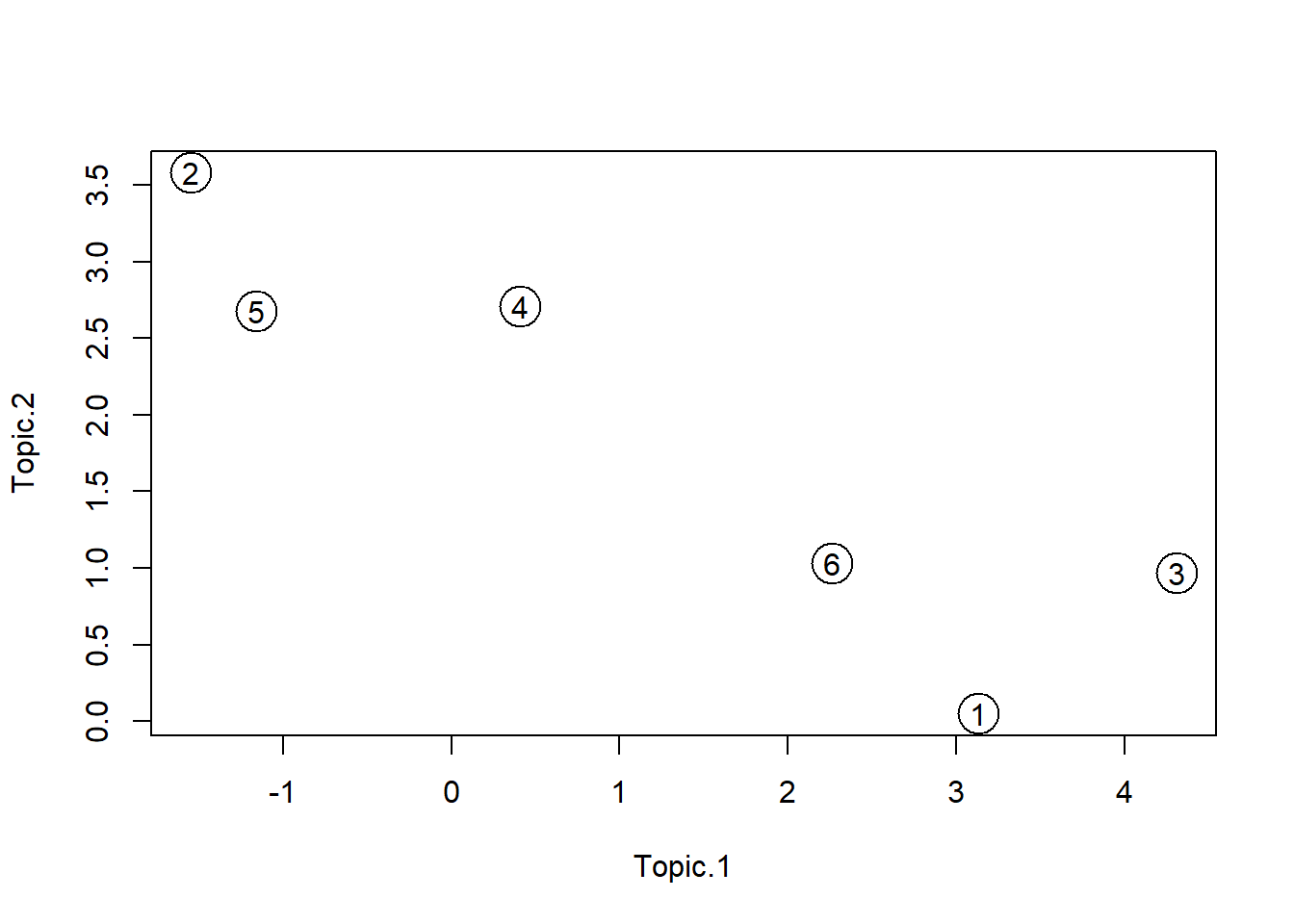
Uniqueness of the solution
The solution is not unique, as you might have noticed (note the difference in Z and B from the illustrative example and the computed Z and B) eventhough \(W\) remains the same. To see why, assume \(T\) is an orthonormal matrix, that is, \(T\) is such that \(TT^t = I\). Then, \(W \simeq ZB = ZTT^tB = (ZT)(T^tB) = Z^*B^*\) where \(Z^* = ZT\), and \(B^* = T^tB\). Thus, (\(Z\), \(B\)) and (\(Z^*\), \(B^*\)) are both equally valid solutions. Therefore, the solution is not unique. This non uniqueness of the solution poses some challenges for inferential studies based on the reduced dimension.
Interpreting the new variables
Again, we use the rows of the \(B\) matrix to infer the meaning of each column of \(Z\). Why? Observed that \[\hat B = (Z^tZ)^{-1}Z^tW\] Let’s define \(F = (Z^tZ)^{-1}Z^t\) with elements \(f_{i,j}\), that is, \(f_{i,j}\) is the value in the \(i^{th}\) row, \(j^{th}\) column of the matrix \(F\). Thus, \(\hat B = FW\) \[ \hat B_{k,p}=\begin{bmatrix}b_{1,1} & b_{1,2} & \cdots & b_{1,p}\\ b_{2,1} & b_{2,2} & \cdots & b_{2,p}\\ \vdots & \vdots & \ddots & \vdots\\ b_{k,1} & b_{k,2} & \cdots & b_{k,p} \end{bmatrix} = \begin{bmatrix}f_{1,1} & f_{1,2} & \cdots & f_{1,n}\\ f_{2,1} & f_{2,2} & \cdots & f_{2,n}\\ \vdots & \vdots & \ddots & \vdots\\ f_{k,1} & f_{k,2} & \cdots & f_{k,n} \end{bmatrix} \begin{bmatrix}w_{1,1} & w_{1,2} & \cdots & w_{1,p}\\ w_{2,1} & w_{2,2} & \cdots & w_{2,p}\\ \vdots & \vdots & \ddots & \vdots\\ w_{n,1} & w_{n,2} & \cdots & w_{n,p} \end{bmatrix} \]
If you still remember matrix operations from high school, note that: \[b_{1,1} = \sum_{l=1}^nf_{1,l}\times w_{l,1} \\ = f_{1,1}w_{1,1}+f_{1,2}w_{2,1}+f_{1,3}w_{3,1}+\cdots+f_{1,n}w_{n,1}\] \[b_{1,2} = \sum_{l=1}^nf_{1,l}\times w_{l,2} \\ = f_{1,1}w_{1,2}+f_{1,2}w_{2,2}+f_{1,3}w_{3,2}+\cdots+f_{1,n}w_{n,2}\]
Observe that the source of any numerical difference between \(b_{1,1}\) and \(b_{1,2}\) is the numerical difference between the first and second column of \(W\) (the \(f_{i,j}\) are exactly the same). Also, observe that, whatever \(F\) is, \(b_{1,1}\) is a total weight of the first variable \(W_1\) (say the counts of word 1 in all the documents). Likewise, \(b_{1,2}\) is a total weight of the second variable \(W_2\) (say the count of the second word in all the documents); and so on untill \(b_{1,p}\). Put differently, \(b_{1,j}\) is a total weight of the word \(W_j\). Thus, the coefficients \([b_{1,1},b_{1,2}, \cdots,b_{1,p}]\) are the total weight of the words \(W_1, W_2, \cdots, W_p\), respectively. If these are words’ weights, it is natural to use the words with highest weights to name row 1 of \(B\). We name the remaining rows of \(B\) in similar fashion.
Also, observe that the elements of the first row of \(B\) are the coefficients of the first column of \(Z\). If row 1 of \(B\) is named, say education for example, then the first column of \(Z\) is an education variable. Hence, the naming of the columns of \(Z\).
The values of the new variables \(Z\)
Again, we have \[\hat Z = WB^t(BB^t)^{-1}\] Let’s define \[N = B^t(BB^t)^{-1}\] Then \[\hat Z = WN\] That is \[ \hat{Z} = \begin{bmatrix} z_{1,1} & z_{1,2} & \cdots & z_{1,k}\\ z_{2,1} & z_{2,2} & \cdots & z_{2,k}\\ \vdots & \vdots & \ddots & \vdots\\ z_{n,1} & z_{n,2} & \cdots & z_{n,k} \end{bmatrix} = \begin{bmatrix} w_{1,1} & w_{1,2} & \cdots & w_{1,p}\\ w_{2,1} & w_{2,2} & \cdots & w_{2,p}\\ \vdots & \vdots & \ddots & \vdots\\ w_{n,1} & w_{n,2} & \cdots & w_{n,p} \end{bmatrix} \begin{bmatrix} n_{1,1} & n_{1,2} & \cdots & n_{1,k}\\ n_{2,1} & n_{2,2} & \cdots & n_{2,k}\\ \vdots & \vdots & \ddots & \vdots\\ n_{p,1} & n_{p,2} & \cdots & n_{p,k} \end{bmatrix} \]
Observe that \[z_{1,1} = \sum_{m = 1}^p n_{m,1}w_{1,m} \\ = n_{1,1}w_{1,1}+ n_{2,1}w_{1,2}+n_{3,1}w_{1,3}+\cdots+n_{p,1}w_{1,p}\] \[z_{1,2} = \sum_{m = 1}^p n_{m,2}w_{1,m} \\ = n_{1,2}w_{1,1}+ n_{2,2}w_{1,2}+n_{3,2}w_{1,3}+\cdots+n_{p,2}w_{1,p}\] \[z_{2,1} = \sum_{m = 1}^p n_{m,1}w_{2,m} \\ = n_{1,1}w_{2,1}+ n_{2,1}w_{2,2}+n_{3,1}w_{2,3}+\cdots+n_{p,1}w_{2,p}\] The numerical difference between \(z_{1,1}\) and \(z_{1,2}\) stems from the numerical difference between the weights in column \(1\) and \(2\) of the weights matrix \(N\) (\(N\) can be seen as a weight matrix). The numerical difference between \(z_{1,1}\) and \(z_{2,1}\) stems from the numerical difference between the words counts in documents \(1\) and \(2\) of the words counts matrix \(W\).
Alternatively, we can think of \(Z\) as a composite index matrix. \(z_{i,j}\) is the value of the index \(j\) in document \(i\). For example, \(z_{1,1}\) is the value of index \(1\) in document \(1\); \(z_{1,2}\) is the value of index \(2\) in document \(1\). Why different index values for the same document? Because each index assigns different weights to the same words. For index \(1\), the weights are the \(n_{m,1}\) (\(m=\{1, 2,\cdots,p\}\)). For the index \(2\), the weights are \(n_{m,2}\). And for the \(k^{th}\) index, the weights are \(n_{m,k}\).
Some variants of the matrix factorization
1- Note that our working example data \(W\) is a count data. Naturally, we would want \(Z\) and \(B\) to have non-negative values. Non-Negative Matrix Factorization was invented to force the elements of \(Z\), and \(B\) to be positive.
2- Moreover, the algorithm presented above assumes no probability distribution. Consequently, it is inapropriate to use \(Z\) for inferential studies (Inferential studies build on probabilistic assumption of the data generating process). Probabilistic matrix factorization algorithms address these concerns. These methods include probabilistic Principal Component Analysis (PPCA), Multinomial Principal Component Analysis (mPCA), Probabilistic Latent Semantic Analysis (PLSA), Latent Dirichlet Allocation (LDA), etc…
3- Traditional matrix factorization methods implicitly or explicitly assume multivariate normal distribution, and decomposes the covariance matrix of the data. Factor Analysis (FA) and Principal Component Analysis (PCA) are two examples.
I hope this introductory exposition of topic modeling provides an intuitive understanding of the why, and how of the subject. Feel free to leave your comments below.