Introduction
My work involves the use and the development of topic modeling algorithms. A surprising challenge I have had is communicating the output of topic modeling algorithms to people not familiar with text analytics. Here is my 10 cents explanation of the LDA output to my econ friends.
The use of text data for economic analysis is gaining attractions. One popular analytical tool is Latent Dirichlet Allocation (LDA), also called topic modeling (Blei, Ng, and Jordan 2003). Succinctly put, topic modeling consists of collapsing a matrix (i.e a spreadsheet) of words counts into a reduced matrix of topics’ proportions within documents. For instance, assume we have a collection of 500 documents, each containing 2000 unique words; this collection of documents (called corpus) can be represented as a dataset of 500 observations and 2000 variables (each word being a variable). Each cell in the matrix represents the count of a word in a document. The matrix is just a regular spreadsheet of data. Clearly, it is almost impossible to draw any insight from that many variables. LDA allows us to collapse the high dimensional dataset into a lower dimension, say a dimension of 10. With 10 variables, there is a hope that some insight can be drawn from the data. Following is a demonstration of LDA.
Example Data
Let’s consider a dataset of U.S. governors’ State of the State Addresses (SoSA). In most states, the governor gives a speech, generally in January, in which he/she lays out his/her priorities for the next fiscal year. Part of the goal of the speech is to explain (or justify) the proposed budget, and hopefully convince the state stakeholders to support the proposed budget. A budget proposal usually involves a reallocation of the state resources, which implies cuts and increases in different lines of the state budget. I collected 596 speeches from governors of the 50 states, spanning from 2001 to 2013.
It is customary in text analytics to delete words that we believe are not “discriminative”. For instance link words such as “the”, “and”, “she”, etc. will not distinguish a Democrat from a Republican. We call this process, pre-processing the data, that is, cleaning the data by removing elements in the texts that we believe are not useful for our analysis.
After pre-processing the data, I am left with a dataset of 596 observations and 1034 words (or variables). You can take a look at the pre-processed data here, or you can download it here. Stemming, that is stripping the words to their roots, is often done to avoid counting related words separately. For example, education, educational, educate are stemmed and become educ.
Example application of LDA
The goal when using LDA is primarily to reduce the dimension of a counts dataset. The hope is that the reduced dimension preserves the essential information contained in the original dataset. Interestingly, the reduced dimension is often more appropriate for statistical analysis, as it “solves” the overfitting problem associated with high dimensional data. Generally, the overfitting problem arises in situations where \(n\), the number of observations, is not big enough to provide reliable estimates of the \(p\) variables’ parameters.
There are several packages in R to implement the LDA model (lda, mallet, and topicmodels). Here I will use the topicmodels package as an example.
# install.packages("topicmodels") # You should run this code once if you don't have topicmodels installed
library(topicmodels) # Load the topicmodels package
url <- url("https://github.com/Salfo/States-Addresses/raw/master/data/SoSA_data_df.RData")
load(url) # Load the data from the url provided
SoSA_topics <- LDA(SoSA_data_df, # The matrix of words counts
k = 2, # The number of topics to construct
method = "Gibbs", # Estimation method
control = list(iter = 3000, # Number of iterations
burnin = 1000, # Thow out the first 1000 estimates
seed = 123)) # To get a reproducible resultsNote that LDA is a matrix factorization algorithm, and a matrix factorization consists of decomposing a matrix into the product of two or more matrices. Intuitively, we can write: \[W_{D,V} \simeq \theta_{D,V}\phi_{K,V}\]
The reduced dimension, \(\theta\) matrix
In this example, \(D=596\), \(V=1034\), \(K=2\). \(\theta\) contains the essential information needed to understand the variation between observations, concerning the speeches. For instance, \(\theta\) can be used to study how Democrats differ from Republicans regarding the relative importance of themes they cover in their speeches. \(\theta\) can be seen as a regular spreadsheet of data, as shown below. For an extended exposition of LDA, see this.
theta_matrix <- posterior(SoSA_topics)$topics # Extract the theta matrix
theta_matrix <- round(as.data.frame(theta_matrix), digits = 3)
names(theta_matrix) <- paste("Topic.", 1:2, sep = "") # Name the columns
head(theta_matrix, n = 10) # Print out the first 10 observations## Topic.1 Topic.2
## Alabama_2001_D_1.txt 0.274 0.726
## Alabama_2002_D_2.txt 0.377 0.623
## Alabama_2003_R_3.txt 0.767 0.233
## Alabama_2004_R_4.txt 0.613 0.387
## Alabama_2005_R_5.txt 0.484 0.516
## Alabama_2006_R_6.txt 0.513 0.487
## Alabama_2007_R_7.txt 0.424 0.576
## Alabama_2008_R_8.txt 0.481 0.519
## Alabama_2009_R_9.txt 0.516 0.484
## Alabama_2010_R_10.txt 0.583 0.417How do we know which themes are covered?
Well, here we imposed the number of themes by setting \(K=2\). To identify the themes, we use the matrix \(\phi\), which presents the relative importance of each word for each theme (or topic).
phi_matrix <- posterior(SoSA_topics)$terms # Extract the phi matrix
phi_matrix <- round(phi_matrix, 3) # Round the numbers to 3 decimals
phi_matrix[, 1:20] # Print out the first 20 words## abil abus academ acceler accept access accomplish accord account
## 1 0.001 0.001 0.000 0 0.001 0.000 0.000 0 0.002
## 2 0.000 0.001 0.001 0 0.000 0.003 0.001 0 0.001
## achiev acknowledg across action activ actual addit address adequ
## 1 0.001 0.001 0.001 0.001 0.001 0.001 0.003 0.005 0
## 2 0.002 0.000 0.002 0.001 0.001 0.000 0.001 0.001 0
## administr adopt
## 1 0.003 0.001
## 2 0.000 0.000It might be more helpful to transpose the \(\phi\) so that by sorting each topic by decreasing order of the words relative weights we can identify the first few most important (in terms of weight) words for the given topic.
T_phi_matrix <- as.data.frame(t(phi_matrix))
names(T_phi_matrix) <- paste("Topic.", 1:2)
T_phi_matrix[1:20, ] # Print out the first 20 words## Topic. 1 Topic. 2
## abil 0.001 0.000
## abus 0.001 0.001
## academ 0.000 0.001
## acceler 0.000 0.000
## accept 0.001 0.000
## access 0.000 0.003
## accomplish 0.000 0.001
## accord 0.000 0.000
## account 0.002 0.001
## achiev 0.001 0.002
## acknowledg 0.001 0.000
## across 0.001 0.002
## action 0.001 0.001
## activ 0.001 0.001
## actual 0.001 0.000
## addit 0.003 0.001
## address 0.005 0.001
## adequ 0.000 0.000
## administr 0.003 0.000
## adopt 0.001 0.000The terms() function of the topicmodels package returns a convenient \(\phi\) matrix that replaces the words weights by the words themselves, after sorting each row of the \(\phi\) matrix.
terms_matrix <- terms(SoSA_topics, 30) # Extract the first 30 most important words for each topic
terms_matrix[1:15, ] # Print out the first 15 words## Topic 1 Topic 2
## [1,] "budget" "school"
## [2,] "fund" "work"
## [3,] "govern" "educ"
## [4,] "peopl" "help"
## [5,] "million" "children"
## [6,] "work" "make"
## [7,] "make" "famili"
## [8,] "public" "nation"
## [9,] "propos" "busi"
## [10,] "servic" "creat"
## [11,] "dollar" "health"
## [12,] "know" "student"
## [13,] "spend" "invest"
## [14,] "increas" "teacher"
## [15,] "program" "care"By exploring the most important words for each topic, it seems reasonable to infer that Topic.1 is about “money”, the budget; and Topic.2 is mostly about education.
In sum, \(\theta\) provides the essential information needed to understand variations or differences between observations; \(\phi\) is used to infer the meaning of each of the \(K\) columns of \(\theta\).
Using \(\theta\) for statistical analysis
Of what uses can we make of \(\theta\)? Quite a lot!
\(\theta\) alone, or combined with other control variables, \(X\), can be used for regular statistical analysis. \(\theta\) has been used for economic analyses. (Brown, Crowley, and Elliott 2016) applied LDA to assess whether the thematic content of financial statement disclosures is informative in predicting intentional misreporting. (Hansen and McMahon 2016) uses LDA in a Factor Augmented Vector Autoregressive modeling framework. I have a working paper exploring the relationship between US governors commitments to their economic agenda as stated in their public statements and the expansion of business establishments in their states (Bikienga 2017). For a survey of the use of LDA and other text analytics tools in economics, see (Gentzkow, Kelly, and Taddy 2017).
Illustration of the use of \(\theta\)
Is there any difference between Democrats and Republicans based on the themes covered in their speeches? To answer this question, we can compute the mean values of the topics by party line. Note that D, R, or I is appended to the rownames of the \(\theta\) shown above. They stand for Democrat, Republican, or Independent.
Here, I am using the rownames to construct additional variables (state, party, and year)
library(stringr)
state_vars <- row.names(theta_matrix) %>%
str_split(pattern = "_") %>% as.data.frame() %>% t()
state_vars <- state_vars[, -4]
state_vars <- data.frame(state_vars)
names(state_vars) <- c("state", "year", "party")
df <- data.frame(theta_matrix, state_vars)
n_obs <- sample(1:596, size = 10)
sample_obs <- df[n_obs,]
sample_obs## Topic.1 Topic.2 state year party
## Florida_2009_R_94.txt 0.381 0.619 Florida 2009 R
## Kansas_2009_D_171.txt 0.422 0.578 Kansas 2009 D
## Maryland_2003_R_204.txt 0.435 0.565 Maryland 2003 R
## Illinois_2010_D_139.txt 0.579 0.421 Illinois 2010 D
## SouthDakota_2007_R_405.txt 0.378 0.622 SouthDakota 2007 R
## Tennessee_2002_R_411.txt 0.399 0.601 Tennessee 2002 R
## Florida_2004_R_89.txt 0.217 0.783 Florida 2004 R
## RhodeIsland_2002_R_534.txt 0.375 0.625 RhodeIsland 2002 R
## Alabama_2003_R_3.txt 0.767 0.233 Alabama 2003 R
## Minnesota_2008_R_241.txt 0.387 0.613 Minnesota 2008 RCompute the topics’ means by party line.
library(dplyr)
library(tidyr)
df_by_party <- df %>%
group_by(party) %>%
summarise(Topic.1 = mean(Topic.1), Topic.2 = mean(Topic.2)) %>%
gather(Topic, Topic_proportion, Topic.1:Topic.2) %>%
mutate(Topic_proportion = round(100*Topic_proportion, 0)) %>%
mutate(pos = c(rep(75, 3), rep(25, 3)))
df_by_party## # A tibble: 6 x 4
## party Topic Topic_proportion pos
## <fct> <chr> <dbl> <dbl>
## 1 D Topic.1 46. 75.
## 2 I Topic.1 62. 75.
## 3 R Topic.1 51. 75.
## 4 D Topic.2 54. 25.
## 5 I Topic.2 38. 25.
## 6 R Topic.2 49. 25.Democrats seem to talk more about education (Topic.2) than Republicans. On average, about 54% of their speeches refers to the education theme, against 49% for Republicans. Conversely, Republicans tend to talk more about budgetary issues than Democrats (51% for Republicans vs. 46% for Democrats).
Clearly, these differences are not huge, and we cannot put too much stock into it. The goal here is to illustrate how one may use the topics distributions, without going into the intricacies of statistical significance.
The above table can be visualized with the help of a stacked bar plot.
library(ggplot2)
library(ggthemes)
library(extrafont)
#library(plyr)
#library(scales)
fill <- c("#add8e6", "#b87333")
p_party <- ggplot() +
geom_bar(aes(y = Topic_proportion, x = party, fill = Topic),
data = df_by_party, stat="identity") +
geom_text(data=df_by_party, aes(x = party, y = pos, label = paste0(Topic_proportion,"%")),
colour="black", family="Tahoma", size=4) +
theme(legend.position="bottom", legend.direction="horizontal",
legend.title = element_blank()) +
labs(x="Political Party", y="Percentage") +
ggtitle("Average Proportion of Topic Covered By Party (%)") +
scale_fill_manual(values=fill) +
theme(axis.line = element_line(size=1, colour = "black"),
panel.grid.major = element_line(colour = "#d3d3d3"), panel.grid.minor = element_blank(),
panel.border = element_blank(), panel.background = element_blank()) +
theme(plot.title = element_text(size = 14, family = "Tahoma", face = "bold"),
text=element_text(family="Tahoma"),
axis.text.x=element_text(colour="black", size = 10),
axis.text.y=element_text(colour="black", size = 10))
p_party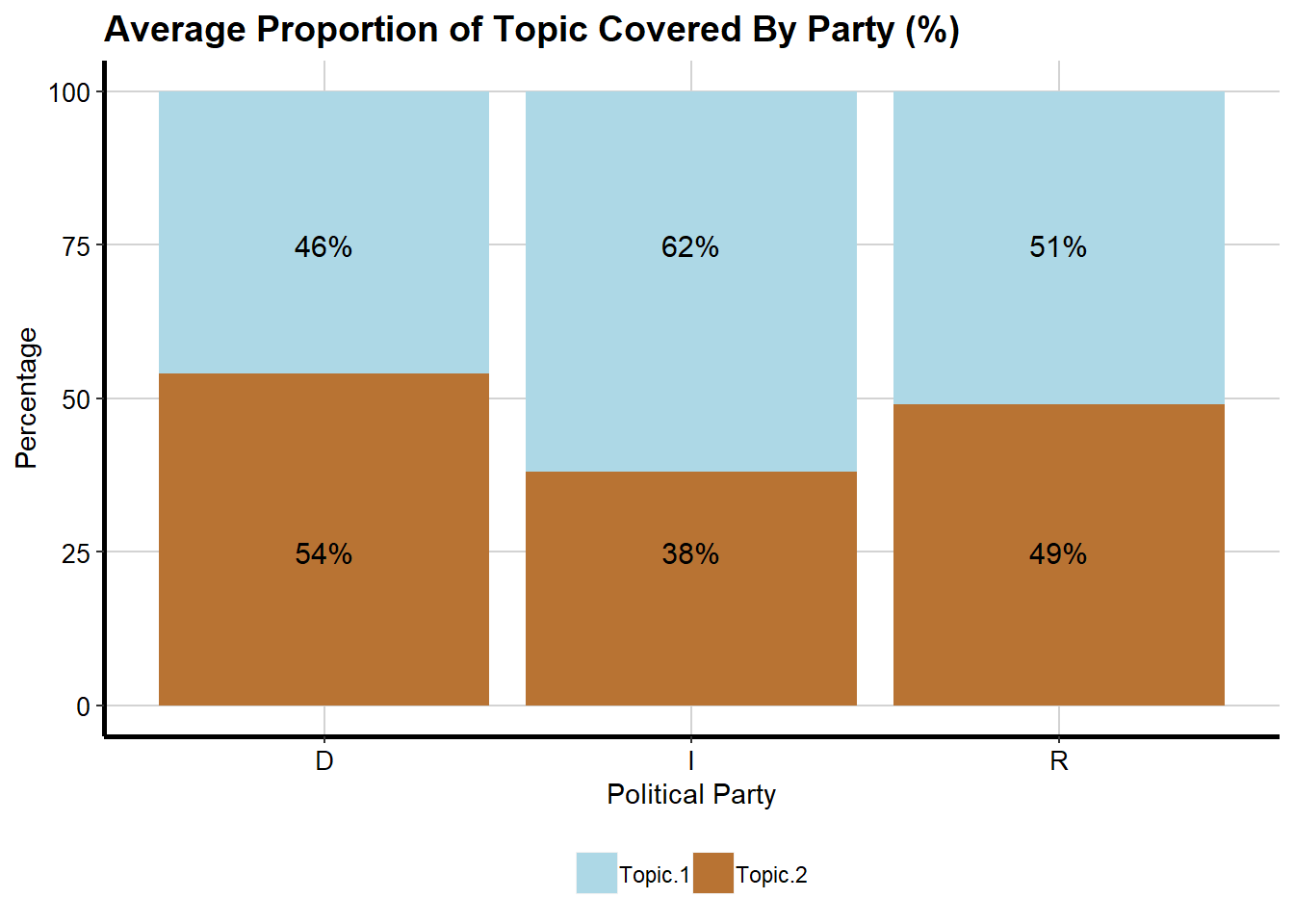
Should we trust the results?
Yes! We should. A mental block I faced when I started exploring topic modeling is trusting the results. If your program is like mine, latent variables models are not covered in your econometrics classes, even though they are widely used in the economics literature. In Macroeconomics, they are termed Factor Augmented Vector Autoregressive models. In Development Economics, they are used to construct indices (Bérenger and Verdier-Chouchane 2007, @Tabellini2010). Factor models approaches are also used as instruments (Bai and Ng 2010).
But, LDA is just another factor model algorithm. It is closely related to principal component analysis (PCA). In the future, I will present the idea of factor models, and why they are “reliable”.
#Conclusion
In sum, topic modeling in general and LDA in particular is a dimension reduction method. It consists of collapsing a matrix of words counts into a reduced matrix of topics distributions. This illustration provides a sense of its usefulness for statistical analysis.
References
Bai, Jushan, and Serena Ng. 2010. “Instrumental Variable Estimation in a Data Rich Environment.” Econometric Theory 26 (6). Cambridge University Press: 1577–1606.
Bérenger, Valérie, and Audrey Verdier-Chouchane. 2007. “Multidimensional Measures of Well-Being: Standard of Living and Quality of Life Across Countries.” World Development 35 (7). Elsevier: 1259–76.
Bikienga, Salfo. 2017. “The Governor as the Entrepreneur in Chief: An Exploratory Analysis.”
Blei, David M., Andrew Y. Ng, and Michael I. Jordan. 2003. “Latent Dirichlet Allocation.” J. Mach. Learn. Res. 3 (March). JMLR.org: 993–1022. http://dl.acm.org/citation.cfm?id=944919.944937.
Brown, Nerissa C, Richard M Crowley, and W Brooke Elliott. 2016. “What Are You Saying? Using Topic to Detect Financial Misreporting.”
Gentzkow, Matthew, Bryan T Kelly, and Matt Taddy. 2017. “Text as Data.” National Bureau of Economic Research.
Hansen, Stephen, and Michael McMahon. 2016. “Shocking Language: Understanding the Macroeconomic Effects of Central Bank Communication.” Journal of International Economics 99. Elsevier: S114–S133.
Tabellini, Guido. 2010. “Culture and Institutions: Economic Development in the Regions of Europe.” Journal of the European Economic Association 8 (4). Oxford University Press: 677–716.